In our previous post, we have discussed about the steps involved in building a machine learning model which is commonly referred to as a pipeline. In this post we’ll be learning about the classification problems.
Classification problem in Machine Learning
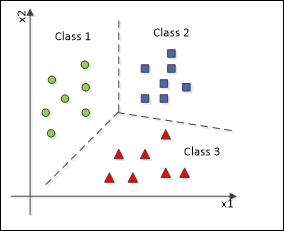
Classification is a sub-category of supervised learning where our objective is to predict the categorical labels. The classification is sub-categorized into 2 types.
- Binary Classification : In this type of classification, the categorical labels are two. For example, to classify whether a mail is spam or not.
- Multi-Class Classification : In this type of classification, the categorical labels are more than two.For example, to detect a handwritten digit.
Algorithms available in Python
Some commonly used classification algorithms provided by Scikit-Learn are listed below
- K-Nearest Neighbors
- Support Vector Machine’s
- Decision Tree Classifiers/Random Forests
- Naive Bayes
- Linear Discriminant Analysis
- Logistic Regression
We’ll be discussing about the algorithms each in detail.So,now let’s begin.
K-Nearest Neighbors Algorithm

K-Nearest Neighbor is the basic and most essential classification algorithm.The KNN mainly based on the rule similar things exist at closer to each other.
How KNN works?
- Load the data
- Initialize k where k is the number of neighbors to be considered to find proximity.
- For each point in the data calculate distance between the current data point and the query point.
- Sort the distances and select the first K points
- Get labels of the first K points and return the most repeating label.
Implementation of KNN in Python

Now,we’ve entered the most interesting part.We are now building a cancer detection model.So, we would use our cancer data which contains 100 records with 10 features each namely id,diagnosis result(severity), radius, texture, perimeter, area, smoothness, compactness, symmetry, fractal dimension.Now, let’s start building our machine learning pipeline.
Data Collection
import pandas as pd
data = pd.read_csv('./Prostate_Cancer.csv')
data.head()
Data Pre-processing
When we take a keen look towards the data, we find some “NA” i.e, missing values and also the column “id” doesn’t play any vital role in model training. So, we resolve them as follows.
#Rescaling Data
data = data.drop('id',axis=1)#Removes the id column from the data.
data = data.dropna()#Removes the rows which contain 'NA' values
data = data.reset_index(drop=True)This removes the “null” values from the data. Now, we observe that the features are of different scales.So, we rescale them as follows
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
scaler.fit(features)
features = pd.DataFrame(scaler.transform(features))
features.head()This rescales all the feature’s into the range 0 to 1. Coming to the labels we need to encode them into numerical values for easy calculations.
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
le.fit(data["diagnosis_result"])
target=pd.DataFrame(le.transform(result),columns=["diagnosis_result"])
target.head()
Now, our data is ready for processing.So, we split the data into parts for testing and training.
from sklearn.model_selection import train_test_split
featureTrain , featureTest , labelTrain , labelTest = train_test_split(features,target)Now, start training our KNN algorithm with the data as follows :
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier()
knn.fit(featureTrain,labelTrain)
trainScore = knn.score(featureTrain,labelTrain)
print(trainScore)
Now, our model is ready for testing. So, we perform the testing as follows :
pred = knn.predict(featureTest)
from sklearn.metrics import classification_report, confusion_matrix
print(confusion_matrix(labelTest,pred))
print(classification_report(labelTest,pred))
So, our model gets an accuracy nearly 0.9583333. You can get the complete code and dataset on my github.
Conclusion
In this post, we’ve discussed about the classification problems, algorithms available in python and KNN algorithm implementation. In the next post we’ll be discussing about recognition of handwritten digits using KNN algorithm. Until then, cheers✌️ .

One response to “Classification in Machine Learning”
[…] our previous post, we’ve discussed classification problems and algorithms available in sklearn module along […]
LikeLike